基本介绍
伴随的电商业务蓬勃发展,推荐系统也受到了格外重视,在通常电商系统中都是采用基于CF(Collaborative filtering)算法原型来做的。该算法是基于这样基本假设:people who agreed in the past will agree in the future 。
说到SVD算法不能不说到Netflix举办的推荐大赛,这次比赛对推荐系统工业界产生了很大影响,伴随着提出了很多算法思路,所以本文也是以这次比赛为主线,参考其中相关的两篇经典论文,两篇文章会上传。
CF算法的挑战:对于每个user ,未知的item 评分会大体上相似,因此对于那些只给少量item有评分的user将会有比较大的预测误差,因为这样的user缺乏足够信息做预测。
Netflix比赛中最简单直观思路就是利用KNN算法思想,对于某个user 某个未评分的item,找到那个user 近邻的users,然后多个近邻user通过相似性加权来预测这个未评分的item,这个思路很简单实现上也不难,但是这里有个关键问题就是如何计算近邻,如何定义近邻的相似性,我们通过计算users 和 objects特征来计算相似性,但是这个特征很难去构建好。
另外一种思路:matrix factorization 矩阵分解,这其中最常用的就是Singular Value Decomposition算法,SVD直接找到每个user和object的特征,通过user 和object特征对未评分的item进行评分预测。
SVD
SVD跟别的矩阵分解算法相比:没有强加任何限制并且更容易实现

上面是最基本的SVD算法形态,预测函数p 通常就是用简单的dot product 运算,我们知道当我们把一个问题损失函数定义好了,下面要做的就是最优化的问题。
这个算法考虑到评分区间问题,需要把预测值限定在指定评分区间

对上面损失函数求偏导如公式(5)(6)所示。
Batch learning of SVD
所以整个算法流程就如下:(Batch learning of SVD)

然后论文中也给出了如何给U、V矩阵赋初值的算法。
公式中a是评分的下界,n(r)是在[-r,r]的均匀分布,上面提到的SVD算法是其最标准的形式,但是这个形式不是和大规模并且稀疏的矩阵学习,在这种情况下梯度下降会有很大的方差并且需要一个很小的学习速率防止发散。
前面提到了Batch learning of SVD ,我们会发现一个问题就是:如果评分矩阵V 有一些小的变动,比如某个user增加了评分,这是我们利用Batch learning of SVD 又需要把所有数据学习一次,这会造成很大的计算浪费。

如上所述我们每次针对Ui :feature vector of user i 进行学习更新
更极端的情况我们可以针对每一个评分来进行学习如下图:

Incomplete incremental learning of SVD
针对上面基于某个user 学习或者基于某个评分学习算法我们称为增量学习(incremental learning)

算法 2 是基于某个user 的 叫做非完全的增量学习
Complete incremental learning of SVD

算法 3 是基于某个评分进行更新的算法,叫做完全增量学习算法。
算法3还可以有一些改进提升空间:加入per-user bias and per-object bias

在论文结论部分:batch learning or incomplete incremental learning 需要一个很小的学习速率并且跟 complete incremental learning 相比性能不稳定,所以综合得出结论就是complete incremental learning 是对于millions 训练数据最好选择。
Mahout中SVD实现
在Mahout中也会发现时基于complete incremental learning 算法进行的实现
protected void updateParameters(long userID, long itemID, float rating, double currentLearningRate) { int userIndex = userIndex(userID); int itemIndex = itemIndex(itemID); double[] userVector = userVectors[userIndex]; double[] itemVector = itemVectors[itemIndex]; double prediction = predictRating(userIndex, itemIndex); double err = rating - prediction; // adjust user bias userVector[USER_BIAS_INDEX] += biasLearningRate * currentLearningRate * (err - biasReg * preventOverfitting * userVector[USER_BIAS_INDEX]); // adjust item bias itemVector[ITEM_BIAS_INDEX] += biasLearningRate * currentLearningRate * (err - biasReg * preventOverfitting * itemVector[ITEM_BIAS_INDEX]); // adjust features for (int feature = FEATURE_OFFSET; feature < numFeatures; feature++) { double userFeature = userVector[feature]; double itemFeature = itemVector[feature]; double deltaUserFeature = err * itemFeature - preventOverfitting * userFeature; userVector[feature] += currentLearningRate * deltaUserFeature; double deltaItemFeature = err * userFeature - preventOverfitting * itemFeature; itemVector[feature] += currentLearningRate * deltaItemFeature; } } private double predictRating(int userID, int itemID) { double sum = 0; for (int feature = 0; feature < numFeatures; feature++) { sum += userVectors[userID][feature] * itemVectors[itemID][feature]; } return sum; } Neflix比赛胜出文章--SVD++
现在工业界通常依赖的是CF协同过滤算法,协同过滤算法当中最成功方法有两个:1. neighborhood models 通过分析商品和users相似性来构建的模型 2. latent factor models 直接构建users and products profile。
neighborhood method:关键在于计算items or users的关系,基于user 和item 是两种不同的方式,在这里有比较详细对比分析:
Latent factor model:如SVD 通过把items 和users 转换到latent factor space,因而可以使得items 和 users 直接可以比较。
SVD直观理解的描述,假设问一个朋友喜欢什么类型音乐,他列出来了一些艺术家,根据经验知识我们知道他喜欢是古典音乐和爵士音乐。这种表达不是那么精确但是也不是太不精确。如果iTunes 进行歌曲推荐是基于数百万个流派而不是基于数十亿歌曲进行推荐,就能运行的更快;而且对于音乐推荐而言效果不会差太多。SVD就是起到了对数据进行提炼的作用,它从原始数据各个物品偏好中提炼出数量较少但更有一般性的特征。这种思想刚好解决了推荐中如下case:两个用户都是汽车爱好者,但是表现喜爱的是不同品牌,如果传统计算相似性两个用户不相似,如果使用SVD就能发现两者都是汽车爱好者。详细参考:
Netflix 比赛给大家经验是:neighborhood models 和 Latent factor model各自擅长解决不同层次的数据结构。neighborhood models 擅长解决非常 localized 关系,因此这个模型无法捕捉到用户数据中微弱的信号。Latent factor model 擅长全面评估items的联系,但是在小的 数据集上不擅长发现强联系,两者各自擅长某些case,所以自然两者擅长不同我们想把两者优势融合。这篇论文创新是并联起来两个算法在一块,而不是以前做过先使用某个算法得到输出,再在输出上用另外一个算法。

上面描述的是一个:Baseline estimates
下面说下一个通常的neighborhood model

上述方法是最经典邻域模型方法,但是作者提出了不同看法,上面模型在正式模型中不可以调整,相似性衡量阻断了两个items,没有分析整个邻居集下的数据,当邻居信息是缺失时计算会出问题。

现在参数Wij 不在是根据邻居计算出来的,而是通过数据最优化得到Wij的值。现在理解Wij可以为 baseline estimate 的一个 offsets。
现在预测函数形式:考虑了implicit feedback

考虑正则化项的损失函数:
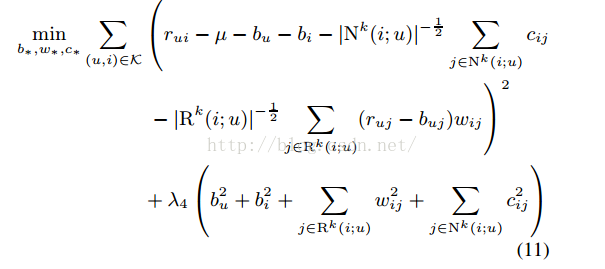
更新规则也就是简单梯度下降算法:

SVD++算法主体流程:

论文中说到SVD++取得了迄今为止最高的正确率,虽然算法在解释性上不够强大。
下面整合了neighborhood model and 正确率最高的LFM--SVD++

上述算法一个学习迭代过程:
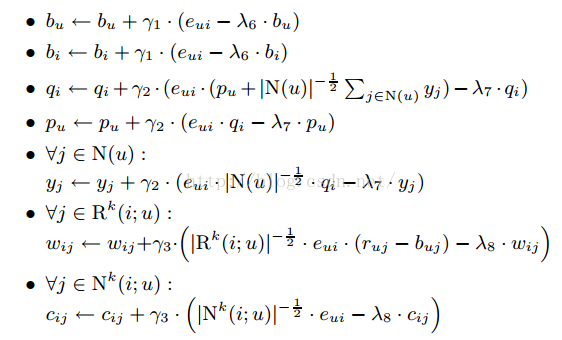
@Override protected void updateParameters(long userID, long itemID, float rating, double currentLearningRate) { int userIndex = userIndex(userID); int itemIndex = itemIndex(itemID); double[] userVector = p[userIndex]; double[] itemVector = itemVectors[itemIndex]; double[] pPlusY = new double[numFeatures]; for (int i2 : itemsByUser.get(userIndex)) { for (int f = FEATURE_OFFSET; f < numFeatures; f++) { pPlusY[f] += y[i2][f]; } } double denominator = Math.sqrt(itemsByUser.get(userIndex).size()); for (int feature = 0; feature < pPlusY.length; feature++) { pPlusY[feature] = (float) (pPlusY[feature] / denominator + p[userIndex][feature]); } double prediction = predictRating(pPlusY, itemIndex); double err = rating - prediction; double normalized_error = err / denominator; // adjust user bias userVector[USER_BIAS_INDEX] += biasLearningRate * currentLearningRate * (err - biasReg * preventOverfitting * userVector[USER_BIAS_INDEX]); // adjust item bias itemVector[ITEM_BIAS_INDEX] += biasLearningRate * currentLearningRate * (err - biasReg * preventOverfitting * itemVector[ITEM_BIAS_INDEX]); // adjust features for (int feature = FEATURE_OFFSET; feature < numFeatures; feature++) { double pF = userVector[feature]; double iF = itemVector[feature]; double deltaU = err * iF - preventOverfitting * pF; userVector[feature] += currentLearningRate * deltaU; double deltaI = err * pPlusY[feature] - preventOverfitting * iF; itemVector[feature] += currentLearningRate * deltaI; double commonUpdate = normalized_error * iF; for (int itemIndex2 : itemsByUser.get(userIndex)) { double deltaI2 = commonUpdate - preventOverfitting * y[itemIndex2][feature]; y[itemIndex2][feature] += learningRate * deltaI2; } } } private double predictRating(double[] userVector, int itemID) { double sum = 0; for (int feature = 0; feature < numFeatures; feature++) { sum += userVector[feature] * itemVectors[itemID][feature]; } return sum; }